 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery9D-21M: Large-Scale Real-World 9D Canonicalization of Everyday Objects
May 27, 2026Estimating the 9D pose of everyday objects from a single real-world image remains challenging. This is largely due to the lack of large-scale supervision. Most existing datasets either rely heavily on synthetic renderings or provide limited coverage of real-world objects: the largest real-world 9D pose dataset to date contains only 17K annotated objects across 9 categories. We address this gap with Every9D-21M, a dataset of 9D pose annotations for 21.8M real-world images from 109K object- centric videos spanning 700 everyday object categories - two orders of magnitude larger than prior real-world 9D pose benchmarks in both image and category count. To achieve this scale, we leverage object-centric videos by reconstructing object- level point clouds via multi-view geometry and aligning similar instances into a shared canonical coordinate frame. Canonical poses are manually annotated for only a small set of reference objects (fewer than 0.01% of all images) and propagated to the remaining instances via cross-instance alignment. All propagated canonical poses are then verified from multiple viewpoints. We further introduce cross-category orientation rules that induce category-level symmetries, enabling symmetry-aware evaluation. Beyond establishing dedicated training and evaluation splits as a benchmark for 9D pose foundation models, we show that training on Every9D-21M improves performance on ImageNet3D and PASCAL3D+, and generalizes to HANDAL substantially better than training on ImageNet3D. Data and code are available at https://github.com/GenIntel/Every9D.
Category-Level 3D Correspondence in Camera Space via Morphable Object Priors
May 27, 2026Understanding 3D objects from images is fundamental to robotics and AR/VR applications. While recent work has made progress in category-level pose estimation, current representations fail to capture the fine-grained semantics needed for reasoning about object parts, functions, and interactions. In this work, we study category-level 3D correspondence in camera space -- predicting, from a single image, 3D locations that remain consistent across instances within a category -- and show that it can emerge without explicit correspondence supervision by learning a shared morphable object prior. To enable research in this direction, we introduce HouseCorr3D, the first large-scale benchmark for monocular category-level 3D correspondence with 178k images across 50 household object categories, 280 unique instances, and 3D keypoint annotations directly on CAD models. Crucially, HouseCorr3D provides amodal correspondence labels for occluded regions and explicit symmetry annotations, addressing key limitations of existing datasets. We further propose Morpheus, a method that learns morphable category-level shape priors by disentangling canonical shape, deformation, and object pose. Through this shared canonical grounding, semantically meaningful 3D correspondences in camera space emerge implicitly. These emerging 3D correspondences set a new state of the art on HouseCorr3D, demonstrating that semantic 3D object understanding can arise without direct correspondence supervision. Data and code are publicly available at https://github.com/GenIntel/HouseCorr3D.
Common3D: Self-Supervised Learning of 3D Morphable Models for Common Objects in Neural Feature Space
Apr 30, 20253D morphable models (3DMMs) are a powerful tool to represent the possible shapes and appearances of an object category. Given a single test image, 3DMMs can be used to solve various tasks, such as predicting the 3D shape, pose, semantic correspondence, and instance segmentation of an object. Unfortunately, 3DMMs are only available for very few object categories that are of particular interest, like faces or human bodies, as they require a demanding 3D data acquisition and category-specific training process. In contrast, we introduce a new method, Common3D, that learns 3DMMs of common objects in a fully self-supervised manner from a collection of object-centric videos. For this purpose, our model represents objects as a learned 3D template mesh and a deformation field that is parameterized as an image-conditioned neural network. Different from prior works, Common3D represents the object appearance with neural features instead of RGB colors, which enables the learning of more generalizable representations through an abstraction from pixel intensities. Importantly, we train the appearance features using a contrastive objective by exploiting the correspondences defined through the deformable template mesh. This leads to higher quality correspondence features compared to related works and a significantly improved model performance at estimating 3D object pose and semantic correspondence. Common3D is the first completely self-supervised method that can solve various vision tasks in a zero-shot manner.
Unsupervised Learning of Category-Level 3D Pose from Object-Centric Videos
Jul 05, 2024



Category-level 3D pose estimation is a fundamentally important problem in computer vision and robotics, e.g. for embodied agents or to train 3D generative models. However, so far methods that estimate the category-level object pose require either large amounts of human annotations, CAD models or input from RGB-D sensors. In contrast, we tackle the problem of learning to estimate the category-level 3D pose only from casually taken object-centric videos without human supervision. We propose a two-step pipeline: First, we introduce a multi-view alignment procedure that determines canonical camera poses across videos with a novel and robust cyclic distance formulation for geometric and appearance matching using reconstructed coarse meshes and DINOv2 features. In a second step, the canonical poses and reconstructed meshes enable us to train a model for 3D pose estimation from a single image. In particular, our model learns to estimate dense correspondences between images and a prototypical 3D template by predicting, for each pixel in a 2D image, a feature vector of the corresponding vertex in the template mesh. We demonstrate that our method outperforms all baselines at the unsupervised alignment of object-centric videos by a large margin and provides faithful and robust predictions in-the-wild. Our code and data is available at https://github.com/GenIntel/uns-obj-pose3d.
SF2SE3: Clustering Scene Flow into SE-Motions via Proposal and Selection
Sep 26, 2022
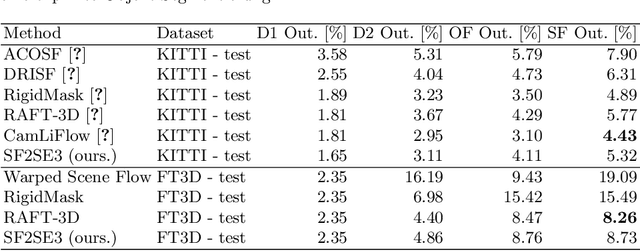

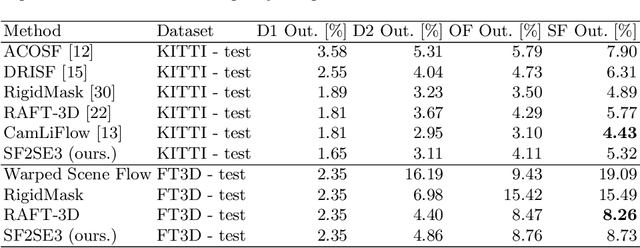
We propose SF2SE3, a novel approach to estimate scene dynamics in form of a segmentation into independently moving rigid objects and their SE(3)-motions. SF2SE3 operates on two consecutive stereo or RGB-D images. First, noisy scene flow is obtained by application of existing optical flow and depth estimation algorithms. SF2SE3 then iteratively (1) samples pixel sets to compute SE(3)-motion proposals, and (2) selects the best SE(3)-motion proposal with respect to a maximum coverage formulation. Finally, objects are formed by assigning pixels uniquely to the selected SE(3)-motions based on consistency with the input scene flow and spatial proximity. The main novelties are a more informed strategy for the sampling of motion proposals and a maximum coverage formulation for the proposal selection. We conduct evaluations on multiple datasets regarding application of SF2SE3 for scene flow estimation, object segmentation and visual odometry. SF2SE3 performs on par with the state of the art for scene flow estimation and is more accurate for segmentation and odometry.